Edge Deployment of Qwen3 Series
Introduction
Qwen3 is the latest generation of large language models in the Qwen series, providing a complete suite of dense models and Mixture-of-Experts (MoE) models. Through large-scale training, Qwen3 has achieved breakthrough progress in reasoning, instruction following, agent capabilities, and multilingual support.
This chapter demonstrates how to perform Qwen3 series model deployment, loading, and conversation on edge devices. Two deployment methods are provided:
- AidGen C++ API
- AidGenSE OpenAI API
In this case, the large language model inference runs on the device side, and the relevant interfaces are called through code to receive user input and return conversation results in real time.
- Device: Rhino Pi-X1
- System: Ubuntu 22.04
- Model: Qwen3-1.7B
Supported Platforms
| Platform | Running Method |
|---|---|
| Rhino Pi-X1 | Ubuntu 22.04, AidLux |
Preparation
- Rhino Pi-X1 hardware
- Ubuntu 22.04 system or AidLux system
AidGen Case Deployment
Step 1: Install the AidGen SDK
# Install AidGen SDK
sudo aid-pkg update
sudo aid-pkg -i aidgen-sdk
sudo aid-pkg -i aidgen-qnn236
sudo aid-pkg -i aidgen-qnn240
# Copy test code
cd /home/aidlux/aidllm
cp -r /usr/local/share/aidgen/examples/ ./Step 2: Download Model Resources
Since Qwen3-1.7B is currently in the Model Farm preview section, it must be retrieved via the
mmscommand.
# Log in
mms login
# Search for the model
mms list qwen3
# Download the model
mms get -m Qwen3-1.7B -p w4a16 -c qcs8550 -b qnn2.36 -d /home/aidlux/aidllm/qwen3-1.7b
cd /home/aidlux/aidllm/qwen3-1.7b
unzip qnn236_qcs8550_cl4096.zip
mv qnn236_qcs8550_cl4096/* /home/aidlux/aidllm/Step 3: Create the Configuration File
cd /home/aidlux/aidllm
vim qwen3-1.7b-aidgen-config.jsonCreate the following json configuration file:
{
"backend_type": "genie",
"prefix_path": "kv-cache.primary.qnn-htp",
"model": {
"path": [
"qwen3-1.7b_qnn236_qcs8550_cl4096_1_of_3.serialized.bin.aidem",
"qwen3-1.7b_qnn236_qcs8550_cl4096_2_of_3.serialized.bin.aidem",
"qwen3-1.7b_qnn236_qcs8550_cl4096_3_of_3.serialized.bin.aidem"
]
}
}Step 4: Confirm Resource Files
The file distribution is as follows:
/home/aidlux/aidllm
├── chat-think.txt
├── chat-nothink.txt
├── htp_backend_ext_config.json
├── qwen3-1.7b-aidgen-config.json
├── kv-cache.primary.qnn-htp
├── qwen3-1.7b_qnn236_qcs8550_cl4096_1_of_3.serialized.bin.aidem
├── qwen3-1.7b_qnn236_qcs8550_cl4096_2_of_3.serialized.bin.aidem
├── qwen3-1.7b_qnn236_qcs8550_cl4096_3_of_3.serialized.bin.aidem
├── examplesStep 5: Compile and Run
cd /home/aidlux/aidllm/examples
# Compile
mkdir build && cd build
cmake .. && make
mv test_text_only /home/aidlux/aidllm/
cd /home/aidlux/aidllm/
./test_text_only qwen3-1.7b-aidgen-config.json "hi"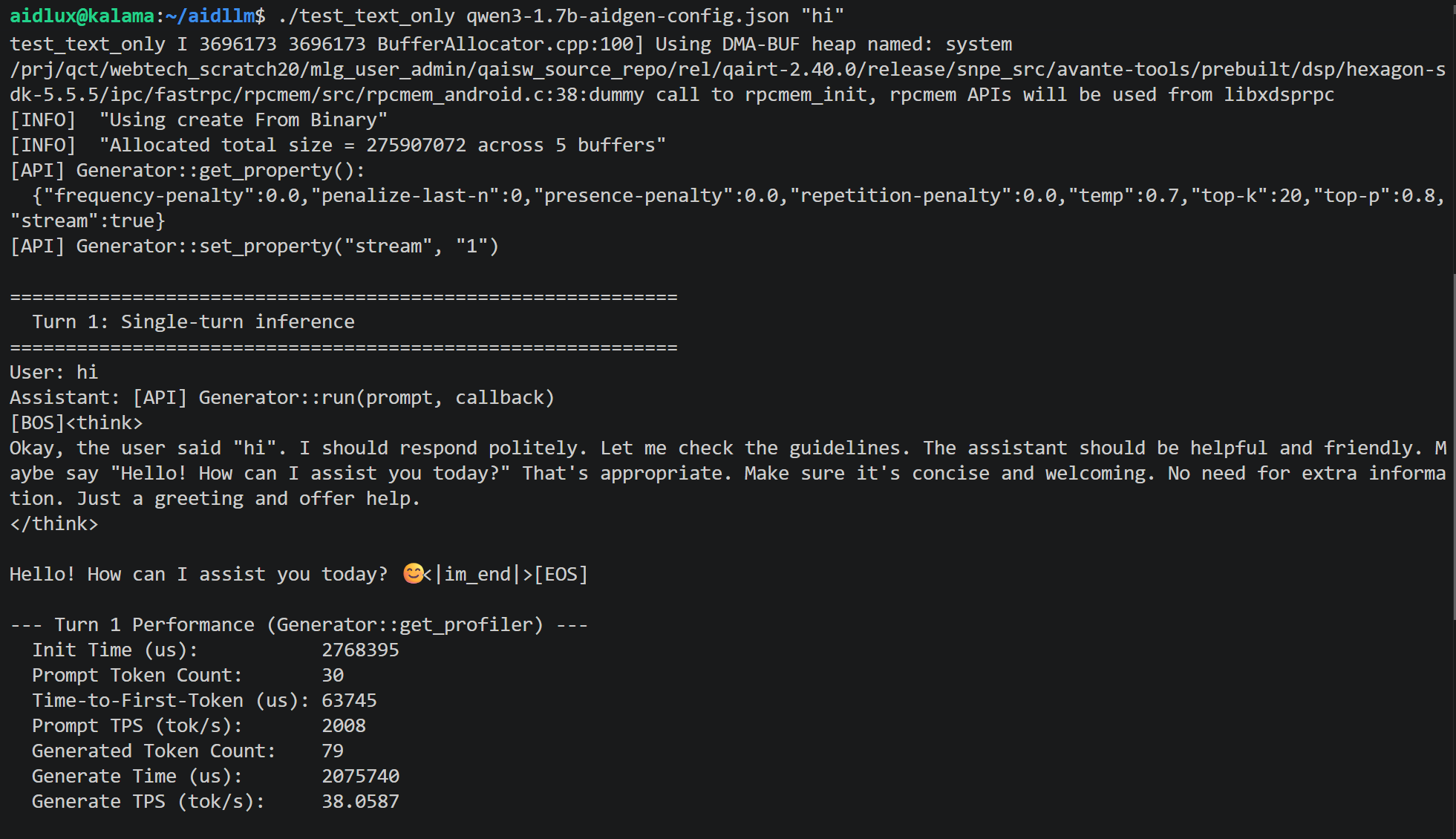
AidGenSE Case Deployment
Step 1: Install AidGenSE
sudo aid-pkg update
# Ensure aidgense is the latest version
sudo aid-pkg remove aidgense
sudo aid-pkg -i aidgense
sudo aid-pkg -i aidgen-sdk
sudo aid-pkg -i aidgen-qnn236
sudo aid-pkg -i aidgen-qnn240Step 2: Model Query & Retrieval
# View models
aidllm remote-list api | grep Qwen3
#------------------------ You can see the Qwen3 models ------------------------
Current Soc : 8550
Name Url CreateTime
----- --------- ---------
qwen3-0.6b-qnn2.36-w4a16-qcs8550 aplux/qwen3-0.6b-qnn2.36-w4a16-qcs8550 2026-05-15 10:59:35
qwen3-1.7b-qnn2.36-w4a16-qcs8550 aplux/qwen3-1.7b-qnn2.36-w4a16-qcs8550 2026-05-15 10:57:37
qwen3-4b-basic-quant-qnn2.36-w4a16-qcs8550 aplux/qwen3-4b-basic-quant-qnn2.36-w4a16-qcs8550 2026-05-15 10:59:47
qwen3-4b-instruct-2507-qnn2.36-w4a16-qcs8550 aplux/qwen3-4b-instruct-2507-qnn2.36-w4a16-qcs8550 2026-05-15 10:57:45
...
# Download qwen3-1.7B-8550
aidllm pull api aplux/qwen3-1.7b-qnn2.36-w4a16-qcs8550Step 3: Start the HTTP Service
# Start the OpenAI API service for the corresponding model
aidllm start api -m qwen3-1.7b-qnn2.36-w4a16-qcs8550
# Check status
aidllm status api
# Stop service: aidllm stop api
# Restart service: aidllm restart api💡Note
The default port is 8888.
Step 4: Chat Test
Chat Test via Web UI
# Install UI frontend service
sudo aidllm install ui
# Start UI service
aidllm start ui
# Check UI service status: aidllm status ui
# Stop UI service: aidllm stop uiAfter the UI service starts, visit http://ip:51104.
Chat Test via Python
import os
import requests
import json
def stream_chat_completion(messages, model="qwen3-1.7b-qnn2.36-w4a16-qcs8550"):
url = "http://127.0.0.1:8888/v1/chat/completions"
headers = {
"Content-Type": "application/json"
}
payload = {
"model": model,
"messages": messages,
"stream": True # Enable streaming
}
# Make request with stream=True
response = requests.post(url, headers=headers, json=payload, stream=True)
response.raise_for_status()
# Read line by line and parse SSE format
for line in response.iter_lines():
if not line:
continue
# print(line)
line_data = line.decode('utf-8')
# Each SSE line starts with the "data: " prefix
if line_data.startswith("data: "):
data = line_data[len("data: "):]
# End marker
if data.strip() == "[DONE]":
break
try:
chunk = json.loads(data)
except json.JSONDecodeError:
# Print and skip when parsing fails
print("Unable to parse JSON:", data)
continue
# Extract the model output token
content = chunk["choices"][0]["delta"].get("content")
if content:
print(content, end="", flush=True)
if __name__ == "__main__":
# Example conversation
messages = [
{"role": "system", "content": ""},
{"role": "user", "content": "Give me a short introduction to large language model."}
]
print("Assistant:", end=" ")
stream_chat_completion(messages)
print() # New line