使用 AidGen 部署 LLM
介绍
端侧部署大语言模型 (Large Language Model, LLM) 指将原本在云端运行的大模型压缩、量化并部署到本地设备上,实现离线、低时延的自然语言理解与生成。本章节以 AidGen 推理引擎为基础,演示如何在边缘设备上完成大语言模型的部署、加载与对话流程。
在本案例中,大语言模型推理运行在设备端,通过 C++ 代码调用相关接口接收用户输入并实时返回对话结果。
- 设备:Rhino Pi-X1
- 系统:Ubuntu 22.04
- 模型:Qwen2.5-0.5B-Instruct
支持平台
| 平台 | 运行方式 |
|---|---|
| Rhino Pi-X1 | Ubuntu 22.04, AidLux |
准备工作
Rhino Pi-X1 硬件
Ubuntu 22.04 系统或 AidLux 系统
准备模型文件
访问 Model Farm: Qwen2.5-0.5B-Instruct 下载模型资源文件
💡注意
选择 QCS8550 芯片
案例部署
步骤一:安装 AidGen SDK
bash
# 安装 AidGen SDK
sudo aid-pkg update
sudo aid-pkg -i aidgen-sdk
# 拷贝测试代码
cd /home/aidlux
cp -r /usr/local/share/aidgen/examples/cpp/aidllm .步骤二:模型资源上传 & 解压
将下载好的模型资源上传至端侧设备中。
解压模型资源至
/home/aidlux/aidllm目录下
bash
cd /home/aidlux/aidllm
unzip Qwen2.5-0.5B-Instruct_Qualcomm\ QCS8550_QNN2.29_W4A16.zip -d .步骤三:资源文件确认
文件分布如下:
bash
/home/aidlux/aidllm
├── CMakeLists.txt
├── test_prompt_abort.cpp
├── test_prompt_serial.cpp
├── aidgen_chat_template.txt
├── chat.txt
├── htp_backend_ext_config.json
├── qwen2.5-0.5b-instruct-htp.json
├── qwen2.5-0.5b-instruct-tokenizer.json
├── qwen2.5-0.5b-instruct_qnn229_qcs8550_4096_1_of_2.serialized.bin
├── qwen2.5-0.5b-instruct_qnn229_qcs8550_4096_2_of_2.serialized.bin步骤四:对话模板设置
💡注意
对话模板请参考模型资源包中的aidgen_chat_template.txt 文件
根据大模型的模板修改 test_prompt_serial.cpp 文件:
cpp
if(prompt_template_type == "qwen2"){
prompt_template = "<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n<|im_start|>user\n{0}<|im_end|>\n<|im_start|>assistant\n";
}步骤五:编译运行
bash
# 安装依赖
sudo apt update
sudo apt install libfmt-dev
# 编译
mkdir build && cd build
cmake .. && make
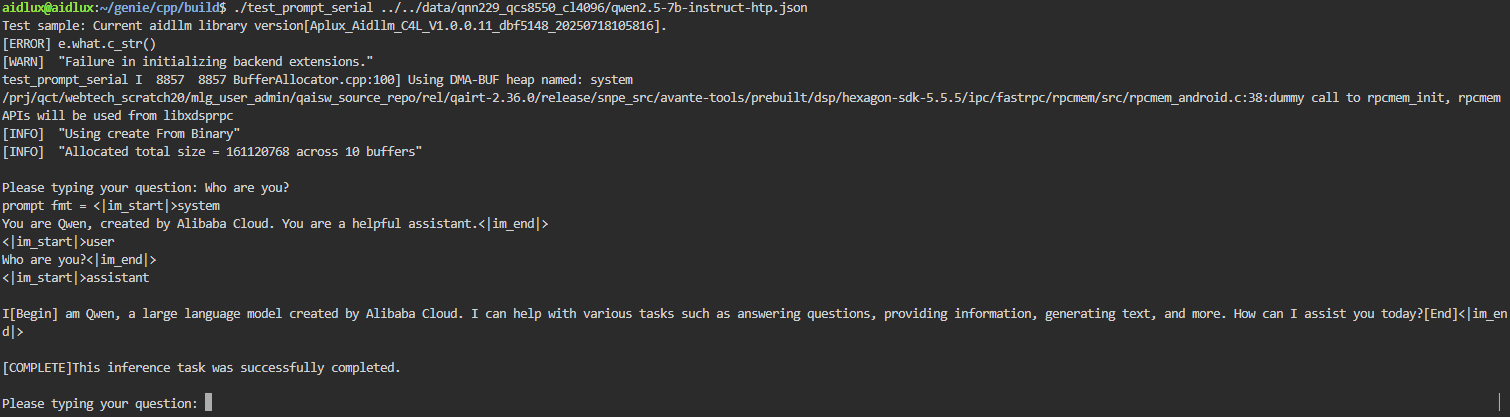
#编译成功后运行 test_prompt_serial
./build/test_prompt_serial qwen2.5-0.5b-instruct-htp.json- 在终端输入对话内容