使用 AidGen 部署 VLM
介绍
端侧部署视觉多模态大模型 (Vision Language Model, VLM) 指将原本在云端运行的大模型压缩、量化并部署到本地设备上,实现离线、低时延的自然语言理解与生成。本章节以 AidGen 推理引擎为基础,演示如何在边缘设备上完成多模态大模型的部署、加载与对话流程。
在本案例中,多模态大模型推理运行在设备端,通过 C++ 代码调用相关接口接收用户输入并实时返回对话结果。
- 设备:Rhino Pi-X1
- 系统:Ubuntu 22.04
- 模型:Qwen2.5-VL-3B (392x392)
支持平台
| 平台 | 运行方式 |
|---|---|
| Rhino Pi-X1 | Ubuntu 22.04, AidLux |
准备工作
Rhino Pi-X1 硬件
Ubuntu 22.04 系统或 AidLux 系统
案例部署
步骤一:安装 AidGen SDK
bash
# 安装 AidGen SDK
sudo aid-pkg update
sudo aid-pkg -i aidgen-sdk
sudo aid-pkg -i aidgen-qnn236
sudo aid-pkg -i aidgen-qnn240
# 拷贝测试代码
mkdir /home/aidlux/aidmlm
cd /home/aidlux/aidmlm
cp -r /usr/local/share/aidgen/examples/ ./步骤二:模型获取
由于 Qwen2.5-VL-3B (392x392) 目前位于 Model Farm 预览板块中,需要通过
mms命令获取
bash
# 登录
mms login
# 查找模型
mms list Qwen2.5-VL-3B
# 下载模型
mms get -m 'Qwen2.5-VL-3B-Instruct (392x392)' -p w4a16 -c qcs8550 -b qnn2.36 -d /home/aidlux/aidmlm/qwen2.5-vl-3b-392
cd /home/aidlux/aidmlm/qwen2.5-vl-3b-392
unzip qnn236_qcs8550_cl2048.zip
mv qnn236_qcs8550_cl2048/* /home/aidlux/aidmlm/步骤三:配置文件创建
bash
cd /home/aidlux/aidmlm
vim config3b_392.json创建如下 json 配置文件
json
{
"backend_type": "genie",
"model": {},
"vlm_model":{
"vision_model_path":"veg.serialized.bin.aidem",
"pos_embed_cos_path":"position_ids_cos.raw",
"pos_embed_sin_path":"position_ids_sin.raw",
"vocab_embed_path":"embedding_weights_151936x2048.raw",
"window_attention_mask_path":"window_attention_mask.raw",
"full_attention_mask_path":"full_attention_mask.raw",
"llm_path_list":[
"qwen2p5-vl-3b_qnn236_qcs8550_cl2048_1_of_1.serialized.bin.aidem"
]
}
}文件分布如下:
bash
/home/aidlux/aidmlm
├── embedding_weights_151936x2048.raw
├── full_attention_mask.raw
├── position_ids_cos.raw
├── position_ids_sin.raw
├── qwen2p5-vl-3b_qnn236_qcs8550_cl2048_1_of_1.serialized.bin.aidem
├── veg.serialized.bin.aidem
├── window_attention_mask.raw
├── examples步骤四:编译运行
bash
cd /home/aidlux/aidmlm/examples
mkdir build && cd build
cmake .. && make
mv test_multimodal /home/aidlux/aidmlm/
cd /home/aidlux/aidmlm/
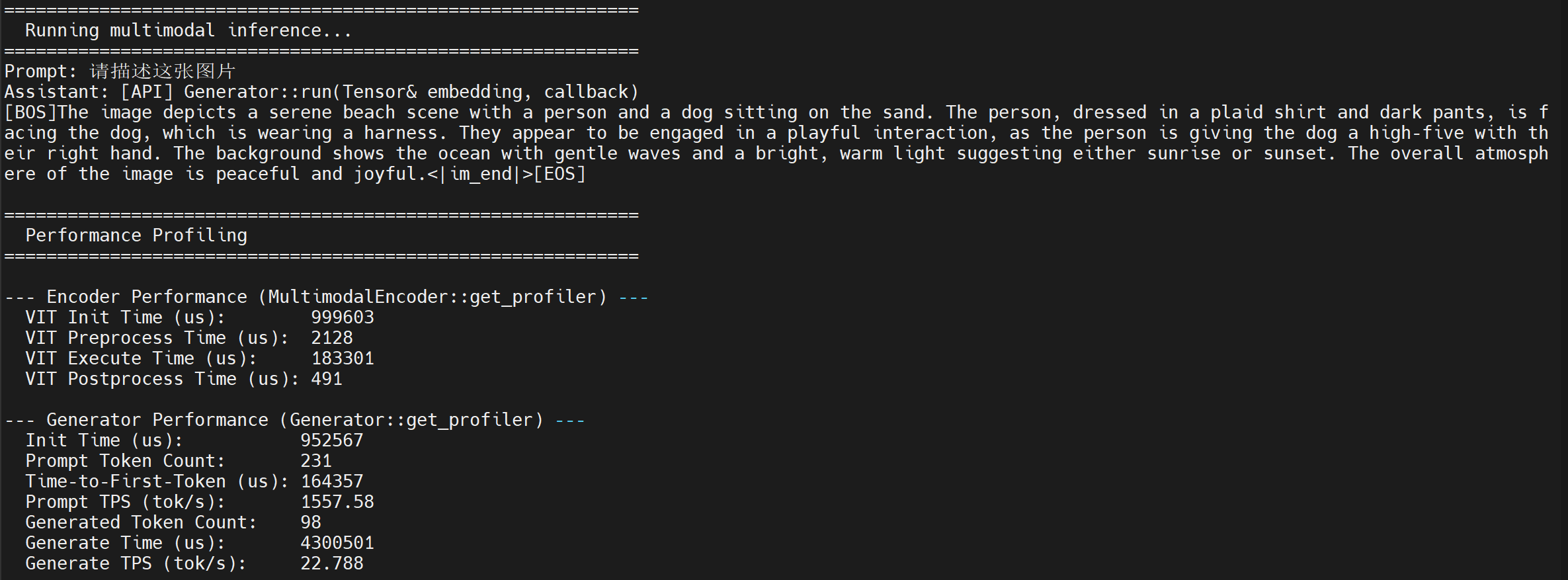
# 手动上传一张图片到 /home/aidlux/aidmlm/ 目录
./test_multimodal config3b_392.json test-1.jpg "请描述这张图片"- 运行结果如下