Deploy VLM with AidGen
Introduction
Edge deployment of Vision Language Models (VLMs) refers to the process of compressing, quantizing, and deploying models that originally ran in the cloud onto local devices. This enables offline, low-latency natural language understanding and generation. Based on the AidGen inference engine, this chapter demonstrates the deployment, loading, and conversation workflow of multimodal large models on edge devices.
In this case, the multimodal model inference runs on the device side. C++ code is used to call relevant interfaces to receive user input and return conversation results in real-time.
- Device: IQ8275
- System: Ubuntu 24.04
- Model: Qwen2.5-VL-3B (392x392)
Supported Platforms
| Platform | Operation Mode |
|---|---|
| IQ8275 | Ubuntu 24.04 |
Prerequisites
IQ8275 hardware
Ubuntu 24.04 system
System Dependency Configuration
Configure the AidLux Package Source
# Download the correct public key
sudo wget -O- https://archive.aidlux.com/ubuntu24/public.key | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/private-aidlux.gpg > /dev/null
# Edit the source list file
sudo vim /etc/apt/sources.list.d/private-aidlux.list
# Add the repository provided by AidLux to the source file
deb [arch=arm64 signed-by=/etc/apt/trusted.gpg.d/private-aidlux.gpg] https://archive.aidlux.com/ubuntu24 noble main
# Update the package cache
sudo apt updateAfter the update is complete, you can use the following command to retrieve the official AidLux SDK dependencies:
sudo apt list | grep aid | grep unknown# Install software
# Must be installed first (not included with the system)
sudo apt install python3 python3-pip libopencv-dev python3-opencv net-tools
# Must be installed before aidlite
sudo apt install aidlux-aistack-base aidrtcm
# Install aidlite and dependencies
sudo apt install aid-lms aidlms-sdk aidlite-sdk cmake
sudo apt-get install libfmt-dev nlohmann-json3-dev
sudo apt install aidlite-*
# DSP support
sudo apt-get install qcom-fastrpc1
sudo apt-get install qcom-fastrpc-dev
# Install aidgen-sdk
sudo apt install aidgen-sdk
sudo apt install aidgen-qnn236
sudo apt install aidgen-qnn240
# Install mms service
sudo apt install aid-mms
# GPU support
sudo apt-add-repository -s ppa:ubuntu-qcom-iot/qcom-ppa
sudo apt install qcom-adreno-cl1
sudo ln -s /usr/lib/aarch64-linux-gnu/libOpenCL.so.1 /usr/lib/aarch64-linux-gnu/libOpenCL.soAfter installation, check that the aidlite and aidgen directories have been added under /usr/local/share:
Device Authorization
Obtain the Device Serial Number
cat /sys/devices/soc0/serial_numberObtain the License File
Provide the serial number to APLUX technical staff to generate a device-specific License file, then place it in the /etc/opt/aidlux/license/AidLuxLics directory.
Activate the License
sudo /opt/aidlux/cpf/aid-lms/manager.sh restartCase Deployment
Step 1: Copy the AidGen SDK Code Example
# Copy the test code
cd /home/ubuntu/aidmlm
cp -r /usr/local/share/aidgen/examples/ ./Step 2: Obtain the Model
Since Qwen2.5-VL-3B (392x392) is currently in the Model Farm Preview section, you need to use the
mmscommand to obtain it.
Using mms requires a Model Farm account login. Please visit Model Farm Account Registration
# Login
mms login
# Search for the model
mms list Qwen2.5-VL-3B
# Download the model
mms get -m 'Qwen2.5-VL-3B-Instruct (392x392)' -p w4a16 -c qcs8550 -b qnn2.36 -d /home/ubuntu/aidmlm/qwen2.5-vl-3b-392
cd /home/ubuntu/aidmlm/qwen2.5-vl-3b-392
unzip qnn236_qcs8550_cl2048.zip
mv qnn236_qcs8550_cl2048/* /home/ubuntu/aidmlm/Step 3: Create Configuration File
cd /home/ubuntu/aidmlm
vim config3b_392.jsonCreate the following json configuration file:
{
"backend_type": "genie",
"model": {},
"vlm_model":{
"vision_model_path":"veg.serialized.bin.aidem",
"pos_embed_cos_path":"position_ids_cos.raw",
"pos_embed_sin_path":"position_ids_sin.raw",
"vocab_embed_path":"embedding_weights_151936x2048.raw",
"window_attention_mask_path":"window_attention_mask.raw",
"full_attention_mask_path":"full_attention_mask.raw",
"llm_path_list":[
"qwen2p5-vl-3b_qnn236_qcs8550_cl2048_1_of_1.serialized.bin.aidem"
]
}
}The file layout is as follows:
/home/ubuntu/aidmlm
├── embedding_weights_151936x2048.raw
├── full_attention_mask.raw
├── position_ids_cos.raw
├── position_ids_sin.raw
├── qwen2p5-vl-3b_qnn236_qcs8550_cl2048_1_of_1.serialized.bin.aidem
├── veg.serialized.bin.aidem
├── window_attention_mask.raw
├── examplesStep 4: Build and Run
cd /home/ubuntu/aidmlm/examples
mkdir build && cd build
cmake .. && make
mv test_multimodal /home/ubuntu/aidmlm/
cd /home/ubuntu/aidmlm/
# Manually upload an image to the /home/ubuntu/aidmlm/ directory
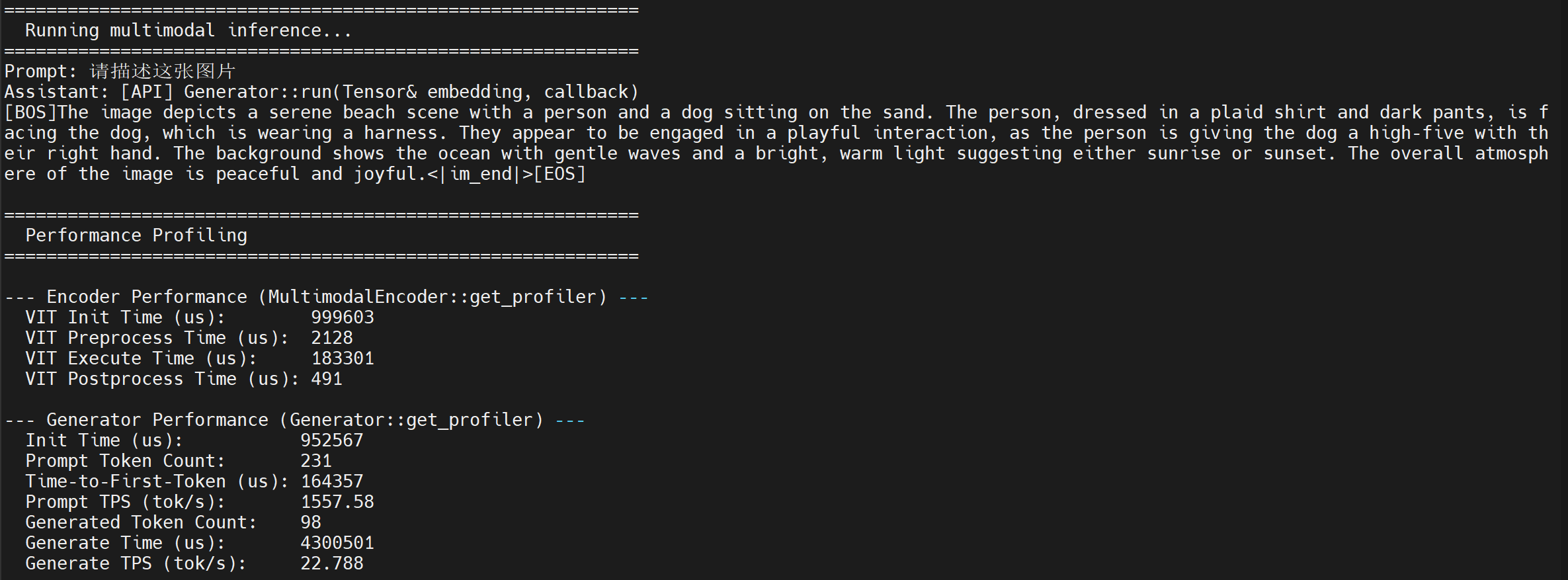
./test_multimodal config3b_392.json test-1.jpg "Please describe the scene in the image"- The execution result is as follows: